-
Historical Voices

By Kayt Button, @kayt_button Today we collect a vast array of readily available information in the form of statistics, stories, reports, and videos available publicly on the internet or through more official channels. These are created by journalists, public servants, and the public at large who are able to self-publish. Before the advent of what has…
-
Call for Papers – Making ‘Big Data’ Human: Doing History in a Digital Age
Alison Richard Building, University of Cambridge, 9th September 2015 With Keynote Speaker Prof. Jane Winters, Professor of Digital History and Head of Publications, Institute of Historical Research In a digital society, it is hard to escape discussions of ‘big data’, massive amounts of information that need database and software techniques for full processing. But beyond…
-
Making ‘Big Data’ Human: Doing History in a Digital Age – Conference Programme
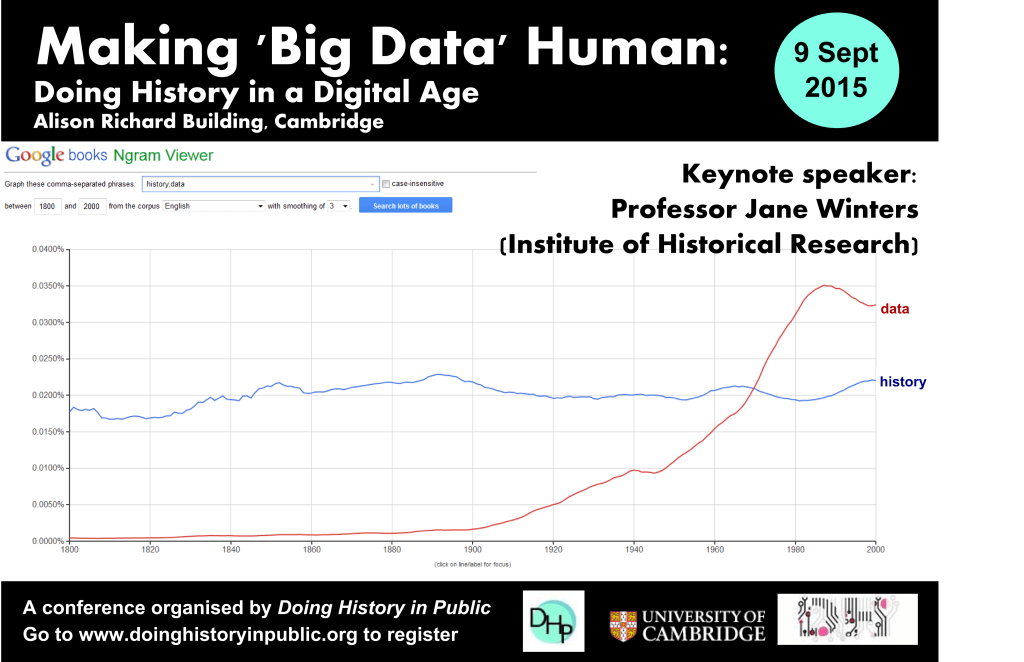
We are pleased to announce the final programme for the “Making ‘Big Data’ Human: Doing History in a Digital Age” conference, as set out below (updated 29/08/15). Registration for the conference is free but please sign up here if you would like to attend. Graduate Student Travel Bursaries – A number of travel bursaries are available for graduate…
-
Reflections on Making ‘Big Data’ Human

By Emily Ward @1066unicorn and Carys Brown @HistoryCarys If there was one thing that the Making Big Data Human conference made clear, it was that ‘Big Data’, and indeed digital methodologies in general, provide some very exciting opportunities to advance historical research. From the ambitious and wide-ranging National Archives’ Traces Through Time project, which looks…

